278 Part 2 ½ Regions of Computer
Space
Section 3 ½ Concurrency: Single-Processor
System
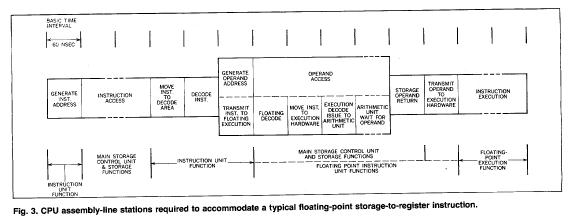
require a number of basic intervals. In order to exploit the assembly line processing approach despite these time disparities, the organizational techniques of storage interleaving [Buchholz, 1962], arithmetic execution concurrency, and buffering are utilized.
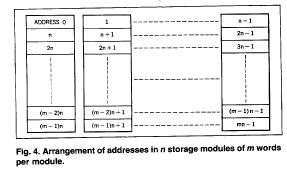
Storage interleaving increases the storage bandwidth by enabling multiple accesses to proceed concurrently, which in turn enhances the assembly line handling of the storage function. Briefly, interleaving involves the splitting of storage into independent modules (each containing address decoding, core driving, data read-out sense hardware, and a data register) and arranging the address structure so that adjacent words-or small groups of adjacent words-reside in different modules. Figure 4 illustrates the technique.
The depth of interleaving required to support a desired concurrency level is a function of the storage cycle time, the CPU storage request rate, and the desired effective access time. The
effective access time is defined as the sum of the actual storage access time, the average time spent waiting for an available storage, and the communication time between the processor and storage.1
Execution concurrency is facilitated first by the division of this function into separate units for fixed-point execution and floating-point execution. This permits instructions of the two classes to be executed in parallel; in fact, as long as no cross-unit dependencies exist, the execution does not necessarily follow the sequence in which the instructions are programmed.
Within the fixed-point unit, processing proceeds serially, one instruction at a time. However, many of the operations required only one basic time interval to execute, and special emphasis is placed on the storage-to-storage instructions to speed up their execution. These instructions (storage-to-storage) enable the Model 91 to achieve a performance rate of up to 7 times that of the System/360 Model 75 for the "translate-and-test" instruction. A number of new concepts and sequences [Litwiller and Adler] were developed to achieve this performance for normally storage access-dependent instructions.
The floating-point unit is given particular emphasis to provide additional concurrency. Multiple arithmetic execution units, employing fast algorithms for the multiply and divide operations and carry look-ahead adders, are utilized [Anderson, Earle, Goldschmidt, and Powers, 1967]. An internal bus has been designed [Tomasulo, 1967] to link the multiple floating-point execution units. The bus control correctly sequences dependent
1Effective access times ranging from 180-600 nsec are anticipated,
although the design of the Model 91 is optimized around 360 nsec. Interleaving
400 nsec/cycle storage modules to a depth of 16 satisfies the 360 nsec
effective access design point.