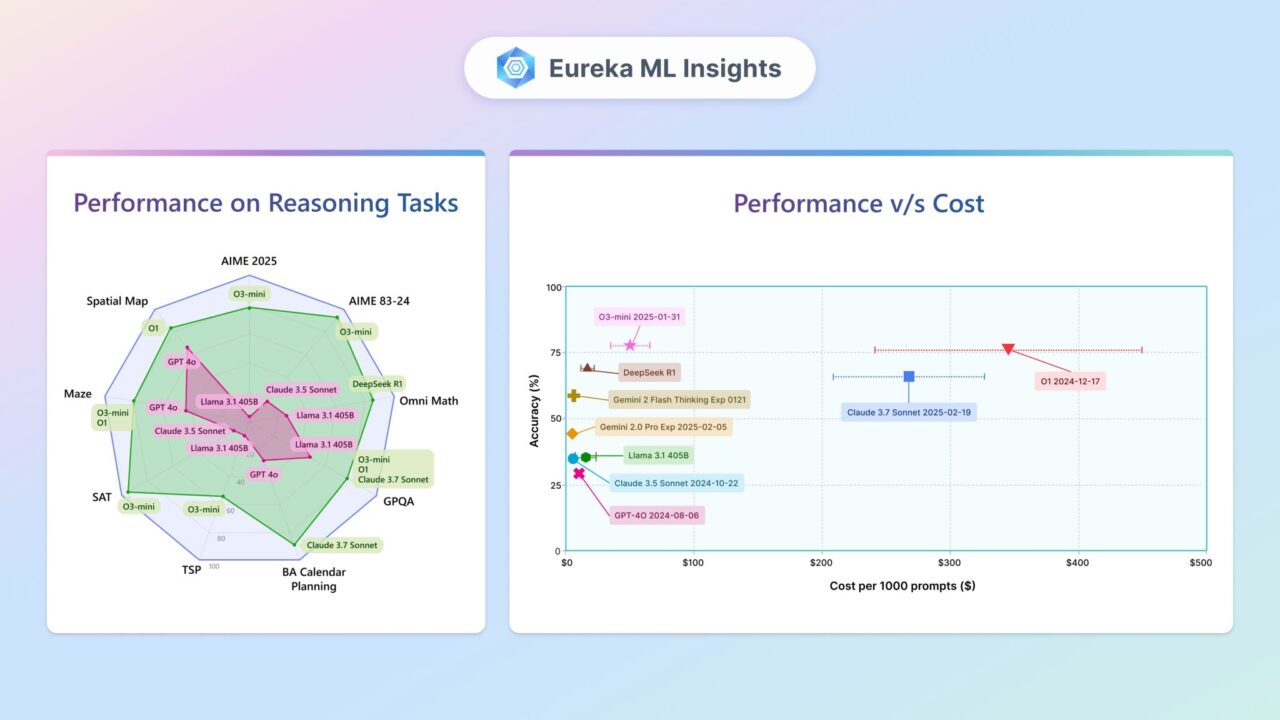
Microsoft Research The AI Revolution in Medicine, Revisited A Microsoft Research Podcast series Learn more Featured Podcasts May 1 Laws, norms, and ethics for AI in health Featured Publications Apr 30 Phi-4-reasoning Technical Report Featured Videos Apr 23 AI for Africa’s Future: Innovation, Equity, and Impact Featured Blogs Apr 23 Research Focus: Week of April 21, 2025 Publication Publications Apr 25 Towards Flood Extent Forecasting: Evaluating a Weather Foundation Model and U-Net for Flood Forecasting News Mar 26 Nuclear fusion: Delivering on the promise of carbon‑free power with the help of AI News Mar 31 Microsoft and ITER to harness the power of AI Publications Jul 1 System comparison using automated generation of relevance judgements in multiple languages News Apr 15 When AI reasoning goes wrong: Microsoft Research shows more tokens can mean more problems Articles Apr 29 Eureka Inference-Time Scaling Insights: Where We Stand and What Lies Ahead Download News Jan 31 Image Search Series Part 1: Chest X-ray lookup with MedImageInsight News Mar 16 Image Search Series Part 2: AI Methods for the Automation of 3D Image Retrieval in Radiology News Apr 23 Optimizing Azure Healthcare Multimodal AI Models for Intel CPU Architecture Publications Apr 21 Agentic Reasoning and Tool Integration for LLMs via Reinforcement Learning Loading Opens in a new tab
Publications Apr 25 Towards Flood Extent Forecasting: Evaluating a Weather Foundation Model and U-Net for Flood Forecasting
Publications Jul 1 System comparison using automated generation of relevance judgements in multiple languages
News Apr 15 When AI reasoning goes wrong: Microsoft Research shows more tokens can mean more problems
News Mar 16 Image Search Series Part 2: AI Methods for the Automation of 3D Image Retrieval in Radiology