
480 EVOLUTION OF COMPUTER BUILDING BLOCKS
The curves for HARPY, ALGOL 68, and QUICKSORT, however, do not show a linear speedup. The reason for this, in each case, is that the problem does not have enough inherent parallelism to keep more than a few processors busy all the time, so that adding more processors does not result in proportionally large speedups. To understand how many processors might effectively be used in larger systems, a number of experiments were conducted. These experiments, which are summarized in the graphs of Figures 19 and 20 were done for the following memory reference patterns.
1. All processors share code, stack, and all data from the memory in a single CM. In other words, the memory bandwidth of an individual CM is the performance bottleneck. This curve indicates that performance cannot be improved by using more than three or four processors. The saturation reference rate of a single CM's memory was measured to be 270K references/second. Now consider more practical cases in which most of the code and local variables are in the local memory of each CM, and only the global data structures are shared. Even if 10 percent of all memory references of the active processors were to global data in the memory of a single CM, the system would saturate between 30 and 40 CMs. To date, we have had no difficulty in distributing shared data structures over the memory of several CMs so that the memory bandwidth of a CM is not a serious constraint.
2. All processors make external references that are mapped back to their own local memory. This case was used to study saturation of the Map Bus and K.map. The curve indicates that the K.map (and Map Bus) saturated when six or seven processors were simultaneously active in this mode; the saturation rate of the
Figure 19. PDE execution time.
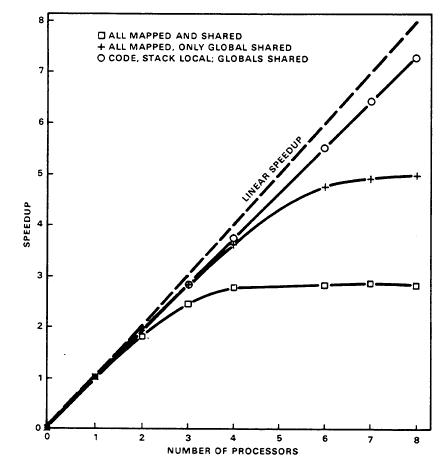
Figure 20. PDE speedup.