
We target at the core problems in image/video understanding and analysis, such as image recognition, image segmentation, image captioning, image parsing, object detection, and video segmentation.
-
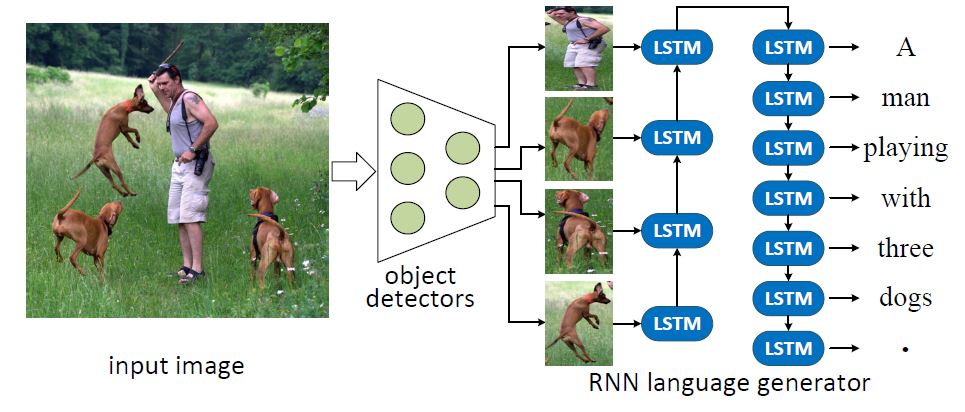
We study the problem of image captioning, i.e., automatically describing an image by a sentence. we formulate the problem of image captioning as a multimodal translation task. Analogous to machine translation, we present a sequence-to-sequence recurrent neural networks (RNN) model for image caption generation. Dierent from most existing work where the whole image is represented by a convolutional neural networks (CNN) feature, we propose to represent the input image as a sequence of detected objects to serve as the source sequence of the RNN model. In this way, the sequential representation of an image can be naturally translated to a sequence of words, as the target sequence of the RNN model. To obtain the sequential representation of an image, objects are first detected by well-trained detectors, and then converted to a sequential representation by some ordering strategies. We also emphasize that in the common space in the RNN model, the objects in the source sequence should be as close as possible to the words in the target sequence. Thus, a new objective function is introduced to measure the similarity between the two modalities in the model. Extensive experiments are conducted to evaluate the proposed approach on benchmark datasets, i.e., Flickr8k, Flickr30k, and MSCOCO, and achieve the state-of-the-art performance. The proposed approach is also evaluated by the evaluation server of MS COCO captioning challenge, and achieves very competitive results.
-
 We study the problem of food image recognition via deep learning techniques. Our goal is to develop a robust service to recognize thousands of popular Asia and Western food. Several prototypes have been developed to support diverse applications. The techniques have been shipped to Bing local search and XiaoIce. We are also developing a prototype called Im2Calories, to automatically calculate the calories and conduct nutrition analysis for a dish image.
We study the problem of food image recognition via deep learning techniques. Our goal is to develop a robust service to recognize thousands of popular Asia and Western food. Several prototypes have been developed to support diverse applications. The techniques have been shipped to Bing local search and XiaoIce. We are also developing a prototype called Im2Calories, to automatically calculate the calories and conduct nutrition analysis for a dish image. -
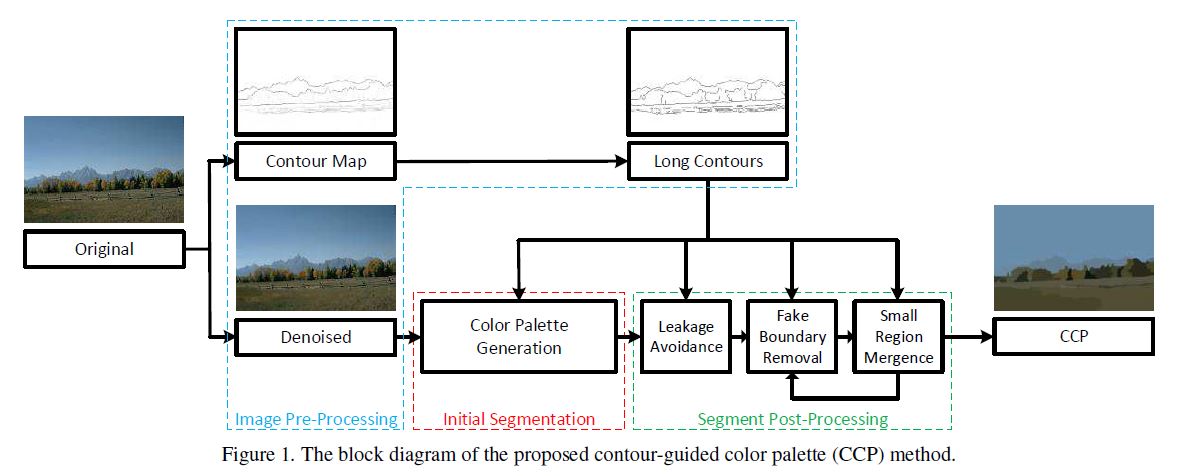
The contour-guided color palette (CCP) 1 is proposed for robust image segmentation. It efficiently integrates contour and color cues of an image. To find representative colors of an image, color samples along long contours between regions, similar in spirit to machine learning methodology that focus on samples near decision boundaries, are collected followed by the mean-shift (MS) algorithm in the sampled color space to achieve an image-dependent color palette. This color palette provides a preliminary segmentation in the spatial domain, which is further fine-tuned by post-processing techniques such as leakage avoidance, fake boundary removal, and small region mergence. Segmentation performances of CCP and MS are compared and analyzed. While CCP offers an acceptable standalone segmentation result, it can be further integrated into the framework of layered spectral segmentation to produce a more robust segmentation. The superior performance of CCP-based segmentation algorithm is demonstrated by experiments on the Berkeley Segmentation Dataset.
-
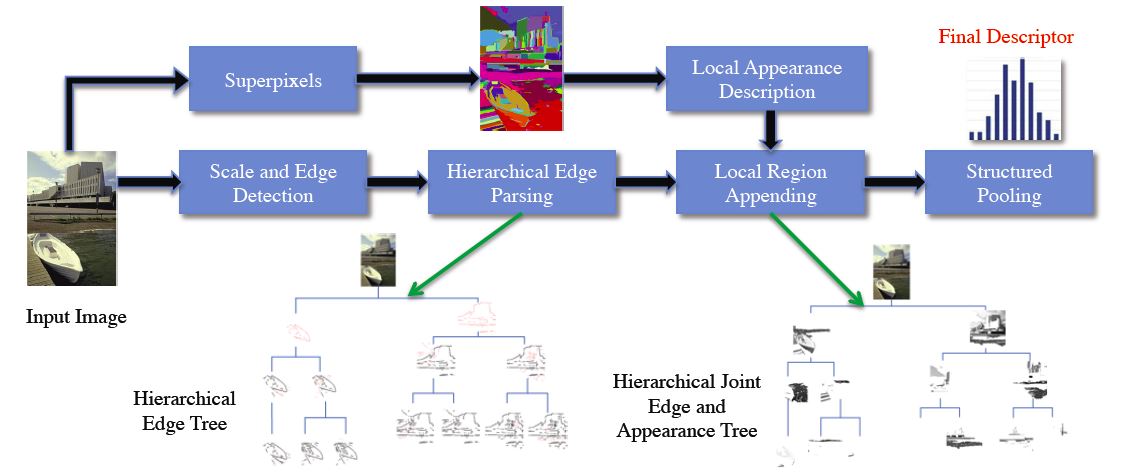
Exploring image structure is a long-standing yet important research subject in the computer vision community. In this paper, we focus on understanding image structure inspired by the “simple-to-complex” biological evidence. A hierarchical shape parsing strategy is proposed to partition and organize image components into a hierarchical structure in the scale space. To improve the robustness and flexibility of image representation, we further bundle the image appearances into hierarchical parsing trees. Image descriptions are subsequently constructed by performing a structural pooling, facilitating efficient matching betweenthe parsing trees. We leverage the proposed hierarchical shape parsing to study two exemplar applications including edge scale refinement and unsupervised “objectness” detection. We show competitive parsing performance comparing to the state-of-the-arts in above scenarios with far less proposals, which thus demonstrates the advantage of the proposed parsing scheme.
-

We study the problem of how to represent and segment objects in a video. To handle the motion and variations of the internal regions of objects, we present an interactive hierarchical supervoxel representation for video object segmentation. First, a hierarchical supervoxel graph with various granularities is built based on local clustering and region merging to represent the video, in which both color histogram and motion information are leveraged in the feature space, and visual saliency is also taken into account as merging guidance to build the graph. Then, a supervoxel selection algorithm is introduced to choose supervoxels with diverse granularities to represent the object(s) labeled by the user. Finally, based on above representations, an interactive video object segmentation framework is proposed to handle complex and diverse scenes with large motion and occlusions. The experimental results show the eectiveness of the proposed algorithms in supervoxel graph construction and video object segmentation.
-
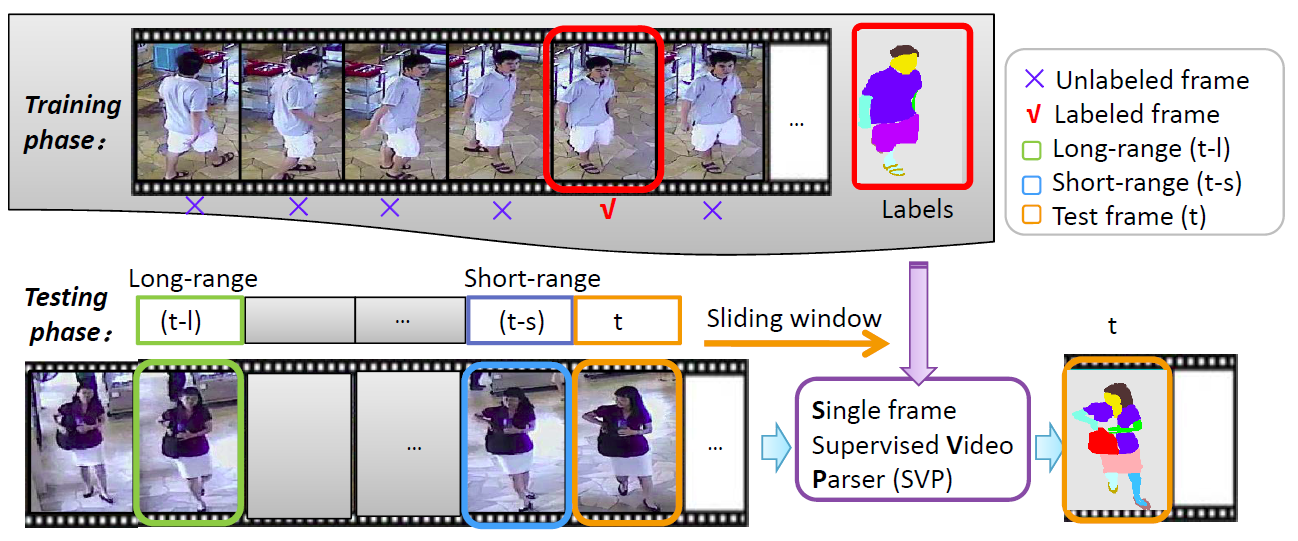
Surveillance video parsing, which segments the video frames into several labels, e.g., face, pants, left-leg, has wide applications [38, 9]. However, pixel-wisely annotating all frames is tedious and inefficient. In this paper, we develop a Single frame Video Parsing (SVP) method which requires only one labeled frame per video in training stage. To parse one particular frame, the video segment preceding the frame is jointly considered. SVP (i) roughly parses the frames within the video segment, (ii) estimates the optical flow between frames and (iii) fuses the rough parsing results warped by optical flow to produce the refined parsing result. The three components of SVP, namely frame parsing, optical flow estimation and temporal fusion are integrated in an end-to-end manner. Experimental results on two surveillance video datasets show the superiority of SVP over state-of-the-arts.
-
TO BE ADDED.