

A key challenge for information retrieval is to model document aboutness. The traditional approach uses term frequency, with more occurrences of a query word indicating that the document is more likely to be about that word. DESM uses multiple document words as aboutness evidence for each query term. For example, for the query term “Albuquerque” the two passages of text below are indistinguishable according to term frequency, each having one occurrence. Our approach considers the presence of related terms such as “population” and “metropolitan”, which is evidence that passage (a) is about Albuquerque while passage (b) merely mentions Albuquerque.

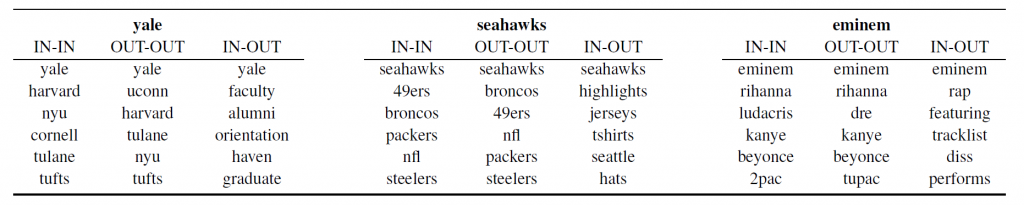
Here we generate our dual embeddings using the well-known tool word2vec (opens in new tab). In most word2vec studies, word embeddings are taken from the model’s input matrix only (IN). In this paper we also use the output matrix (OUT) embeddings. In the table below, the IN vector for “Yale” is close to the IN vector for “Harvard” (IN-IN), but its nearest neighbour in OUT space is “Faculty” (IN-OUT). The single embedding approaches (IN-IN and OUT-OUT) tend to group words of the same type (typical), whereas the dual embedding approach (IN-OUT) groups words that occur together in the training data (topical).
The DESM approach of performing all-pairs comparison with dual embeddings yields positive results on information retrieval testbeds. More details can be found in the publications listed below.