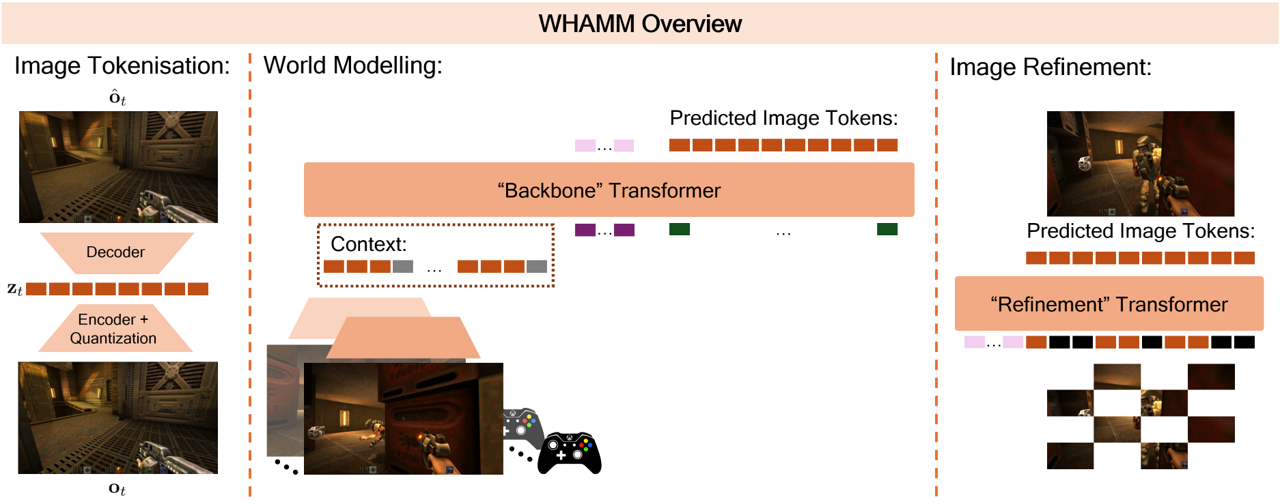
Microsoft Research The AI Revolution in Medicine, Revisited A Microsoft Research Podcast series Learn more Featured Podcasts Apr 17 Empowering patients and healthcare consumers in the age of generative AI Featured Blogs Apr 14 Engagement, user expertise, and satisfaction: Key insights from the Semantic Telemetry Project Featured Articles Apr 4 WHAMM! Real-time world modelling of interactive environments. Featured Blogs Apr 2 VidTok introduces compact, efficient tokenization to enhance AI video processing Download Publication Blogs Apr 18 The Future of AI in Knowledge Work: Tools for Thought at CHI 2025 Publication Articles Apr 18 PEACE project unlocks AI applications in geology using GeoMap Publications Apr 11 Functional Near-Infrared Spectroscopy Feature Extraction with Application in Workload Estimation Publications Apr 12 Imaging Transformer for MRI Denoising: a Scalable Model Architecture that enables SNR<<1 Imaging Publications Jun 11 NTIRE 2025 Challenge on Video Quality Enhancement for Video Conferencing: Datasets, Methods and Results Publications Apr 5 SoundTRC: DNN-based Acoustic Target Region Control Publications Apr 5 SoundTRC: DNN-based Acoustic Target Region Control Publications Apr 1 Make Some Noise: Towards LLM audio reasoning and generation using sound tokens Publications Apr 11 Audio Entailment: Assessing Deductive Reasoning for Audio Understanding News Jan 14 Cancer Survival with Radiology-Pathology Analysis and Healthcare AI Models in Azure AI Foundry Loading Opens in a new tab
Featured Blogs Apr 14 Engagement, user expertise, and satisfaction: Key insights from the Semantic Telemetry Project
Featured Blogs Apr 2 VidTok introduces compact, efficient tokenization to enhance AI video processing Download Publication
Publications Apr 11 Functional Near-Infrared Spectroscopy Feature Extraction with Application in Workload Estimation
Publications Apr 12 Imaging Transformer for MRI Denoising: a Scalable Model Architecture that enables SNR<<1 Imaging
Publications Jun 11 NTIRE 2025 Challenge on Video Quality Enhancement for Video Conferencing: Datasets, Methods and Results
News Jan 14 Cancer Survival with Radiology-Pathology Analysis and Healthcare AI Models in Azure AI Foundry