
The annual conference of the Association for Computing Machinery’s Special Interest Group on Data Communication (SIGCOMM) is always a highlight for those who follow the latest developments in applications, technologies, architectures, and protocols for computer communication. SIGCOMM 2014, to be held in Chicago from August 17 to 22, is definitely the highlight of the year for Victor Bahl, (@SuperBahl) director of Microsoft Research’s Mobility and Networking Research Group (MNR).

Members of the Mobility and Networking Research Group at Microsoft Research: (front) Victor Bahl; (second row) Aakanksha Chowdhery, Ganesh Ananthanarayanan, and Matthai Philipose; (third row) Ratul Mahajan and Meg Walraed-Sullivan; (fourth row) Srikanth Kandula and Peter Bodik; (fifth row) Ming Zhang, Alec Wolman, and Ranveer Chandra; (sixth row) Hongqiang Liu and Stefan Saroiu; and (rear) Sharad Agarwal.

George Varghese
Spotlight: Blog post

MedFuzz: Exploring the robustness of LLMs on medical challenge problems
Medfuzz tests LLMs by breaking benchmark assumptions, exposing vulnerabilities to bolster real-world accuracy.
Two of Bahl’s MNR colleagues are being recognized for significant achievements during SIGCOMM 2014. George Varghese is receiving SIGCOMM’s highest honor, the SIGCOMM Award for lifetime achievement, for sustained and diverse contributions to network algorithmics, with far-reaching impact in both research and industry. He also will deliver the conference’s keynote address. Meanwhile, Ratul Mahajan is receiving the prestigious ACM SIGCOMM Test of Time Paper Award for his 2002 paper Measuring ISP topologies with Rocketfuel, written with University of Washington colleagues Neil Spring and David Wetherall.
It’s also been a bumper year for papers from Microsoft researchers, who wrote or co-wrote nine papers accepted for SIGCOMM, including a Best Paper Award-winning paper, CONGA: Distributed Congestion-Aware Load Balancing for Datacenters, written by Varghese and a host of industrial colleagues. Microsoft researchers Ming Zhang, Srikanth Kandula, and Mahajan contributed to multiple papers, with Zhang and Kandula co-authoring four papers each, a feat only three others have managed in the last 20 years of SIGCOMM.
For Bahl, such recognition is testimony to the high caliber of the scientists within MNR and their academic partners.
“This is a group with amazing depth,” he says. “They’re not just world-class scientists, who routinely come up with great ideas and theory, but they are also very pragmatic. They love nothing better than to solve real-world problems with broad impact. As a research group, we have a real advantage, because we can collaborate in-house with fantastic engineers in Microsoft Azure networking and data-platform teams. This close working relationship is absolutely essential to all parties and key to our continuous success.”
Those interested in how Microsoft’s engineering teams have gained from MNR research over the years need look no further than the Mobility and Networking Research page, in particular the section titled Tech. Transfers. Scroll down the page, and the range of research work by MNR team members becomes evident, from data-center networking to protocols for Xbox One controllers.
Bahl notes that Microsoft’s Wide Area Software Defined Network, the first item on the Tech. Transfers list, was based on the pre-production version of a traffic-engineering system. This work was described in a paper presented last year during SIGCOMM 2013, and the system is now in full production at Microsoft, saving millions of dollars annually by optimizing bandwidth utilization.
Bahl emphasizes two of the Microsoft papers accepted for SIGCOMM this year that are based on close collaboration with the Microsoft Azure teams.
A Breakthrough in Cluster Scheduling
The first is Multi-Resource Packing for Cluster Schedulers, by Robert Grandl and Aditya Akella of the University of Wisconsin-Madison, along with Ganesh Ananthanarayanan, Kandula, and Sriram Rao of Microsoft.
It is challenging to schedule tasks on server clusters. Ideally, a scheduling algorithm should maximize the number of tasks that run at the same time, improving the average job-completion time, as well as maximizing the number of tasks that can run on each server, thus improving server utilization. Historically, though, schedulers were designed for scheduling processors and memory. Extending them to handle storage, which can reside remotely, creates efficiency problems, because of network contention. When this happens, the effective throughput of jobs can decrease, sometimes by more than 40 percent.
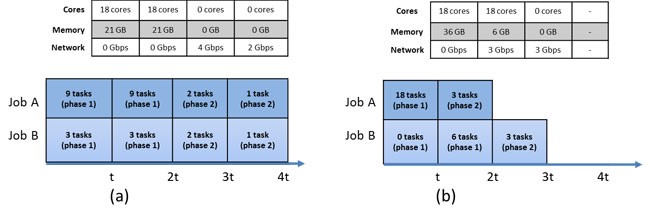
The tables show total cluster utilization with time. Scenario (a) uses fairness-based allocation. Scenario (b), using Tetris, speeds up both jobs.
Researchers and members of the Windows Big Data Platform Team working on a new scheduler achieved a breakthrough when they noticed the problem they had identified was similar to a well-known computer-science problem called multidimensional bin packing. When mapped to big-data systems where data might not be stored in a single location, this problem becomes even tougher because of additional complications. For example, tasks can use less than their peak resources and still finish because their resource requirements change depending on where they are placed—on the same machine or a different one.
Current packing techniques improve cluster throughput but can delay individual jobs. Tetris, the team’s new scheduler, trades off between the two.
Researchers are hardening the code to make it available for Microsoft’s big-data systems, and, possibly, via an open-source storage framework.
Network-State Services Adopted by Azure
The second paper Bahl highlights is A Network-State Management Service, by Peng Sun and Jennifer Rexford of Princeton University, and Mahajan, Ahsan Arefin, Lihua Yuan, and Zhang of Microsoft.

Network-state service: a foundation for data-center-network management.
Statesman, the service described in the paper, is a network-state service (NSS) that has progressed well beyond the prototype stage. Deployed worldwide in all Microsoft Azure data centers since December 2013, it manages more than a million links and 20,000 network devices.
Cloud services, including those operated by Microsoft, support hundreds of millions of Internet users. Beneath these online services, some of the largest data-center networks in the world, often including thousands of network devices and spanning several continents, operate within highly dynamic environments. The sheer number of physical devices means that multiple devices might go offline at any moment for maintenance, firmware upgrades, reconfiguration, or component failures.
Against this complex backdrop, human operators perform management work, much of it manually. It can take hours or even days for human beings to troubleshoot networks, steer traffic away from hotspots, or upgrade firmware on a large number of devices. Meanwhile, users experience degraded service, and network operators suffer losses to the bottom line.
Automated network-management systems are difficult because they must work correctly even if there are component failures or variable delays in communicating with distributed devices. Moreover, there is always the possibility of conflict, for example, between systems for firmware upgrades and traffic engineering. Such conflicts affect the network, sometimes to the extent of disrupting an entire data center.
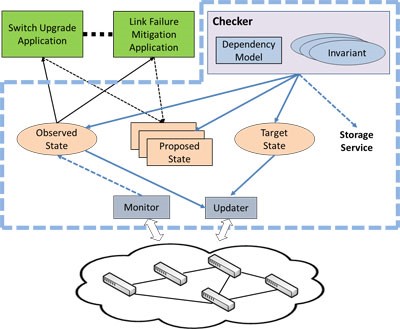
Statesman divides the network state into observed, proposed, and target states.
The Statesman NSS solves such issues by maintaining the states of all network devices and offering that as a service. Network-management systems built atop Statesman can make decisions without worrying about low-level interactions with physical devices. To prevent conflicts and violations, Statesman divides the network state into observed, proposed, and target states. Each management system reads the observed state and produces a proposed state. Statesman merges multiple proposed states into one target state.
This approach was inspired by the way multiple developers collaborate on the same project through a revision-control system. The Azure Networking group quickly adopted Statesman and worked with Zhang and Mahajan to implement a solution for Microsoft’s data centers. A switch-upgrade system and a link-failure-mitigation system have been deployed on top of Statesman, and a traffic-engineering system will be operational soon.
“NSS is critical to our data-center networks,” says Albert Greenberg, director of development for Azure Networking. “It is now fundamental to how we will write the software-defined-networking stack for the core network to bring higher reliability to the backbone. NSS is now a fundamental building block for Microsoft networking.”
Ambitious Objective
Relevance to the real world is core to Bahl’s MNR group objective of producing work that delivers significance and legacy.
“I believe we achieve a lasting legacy in two ways,” Bahl explains. “The first is through research that stands the test of time. The second is through solving real-world problems.”
Given the team’s prominence during SIGCOMM 2014 and its recent contributions to Microsoft Azure, it’s not a stretch to suggest that Bahl and team are achieving their group objective: Significance. Legacy. Impact.
Microsoft Research papers in SIGCOMM 2014
- A Network-State Management Service, by Peng Sun, Princeton University; Ratul Mahajan, Microsoft; Jennifer Rexford, Princeton University; Lihua Yuan, Microsoft; Ming Zhang, Microsoft; and Ahsan Arefin, Microsoft.
- Calendaring for Wide Area Networks, by Srikanth Kandula, Microsoft; Ishai Menache, Microsoft Research; Roy Schwartz, Microsoft; and Spandana Raj Babbula, Microsoft.
- CONGA: Distributed Congestion-Aware Load Balancing for Datacenters, by Mohammad Alizadeh, Cisco; Tom Edsall, Cisco; Sarang Dharmapurikar, Cisco; Ramanan Vaidyanathan, Cisco; Kevin Chu, Cisco; Andy Fingerhut, Cisco; Vinh The Lam, Google; Francis Matus, Cisco; Rong Pan, Cisco; Navindra Yadav, Cisco; and George Varghese, Microsoft.
- Decentralized Task-Aware Scheduling for Data Center Networks, by Fahad R. Dogar, Microsoft Research; Thomas Karagiannis, Microsoft Research; Hitesh Ballani, Microsoft Research; and Ant Rowstron, Microsoft Research.
- Duet: Cloud Scale Load Balancing with Hardware and Software, by Rohan Gandhi, Purdue University; Hongqiang Harry Liu, Yale University; Y. Charlie Hu, Purdue University; Guohan Lu, Microsoft; Jitendra Padhye, Microsoft; Lihua Yuan, Microsoft; and Ming Zhang, Microsoft.
- Dynamic Scheduling of Network Updates, by Xin Jin, Princeton University; Hongqiang Harry Liu, Yale University; Rohan Gandhi, Purdue University; Srikanth Kandula, Microsoft Research; Ratul Mahajan, Microsoft Research; Ming Zhang, Microsoft Research; Jennifer Rexford, Princeton University; and Roger Wattenhofer, ETH Zurich.
- Friends, not Foes — Synthesizing Existing Transport Strategies for Data Center Networks, by Ali Munir, Michigan State University; Ghufran Baig, LUMS; Syed M. Irteza, LUMS; Ihsan A. Qazi, LUMS; Alex X. Liu, Michigan State University; and Fahad R. Dogar, Microsoft Research.
- Multi-Resource Packing for Cluster Schedulers, by Robert Grandl, Microsoft and the University of Wisconsin-Madison; Ganesh Ananthanarayanan, Microsoft and the University of California, Berkeley; Srikanth Kandula, Microsoft; Sriram Rao, Microsoft; and Aditya Akella, Microsoft and the University of Wisconsin-Madison.
- Traffic Engineering with Forward Fault Correction, by Hongqiang Harry Liu, Yale University; Srikanth Kandula, Microsoft Research; Ratul Mahajan, Microsoft Research; Ming Zhang, Microsoft Research; and David Gelernter, Yale University.


