
By Janie Chang, Writer, Microsoft Research
If there are network tools for troubleshooting complex corporate networks, then surely there must be simpler, low-end tools to assist the home or small-business network administrator. That was Victor Bahl (opens in new tab)’s assumption when he went in search of solutions for managing his home network. But Bahl, principal researcher and manager of Microsoft Research Redmond (opens in new tab)’s Networking Research Group (opens in new tab) (NRG) was surprised to find that even though small and medium businesses (SMB) constitute a multibillion-dollar market, he could not find any off-the-shelf products to address SMB networking needs.

Microsoft Redmond’s NetMedic team (from left): Sharad Agarwal, Jitendra Padhye, Victor Bahl, Ratul Mahajan, and Srikanth Kandula.

About Microsoft Research
Advancing science and technology to benefit humanity
What he found—or rather, didn’t find—led Bahl and Ratul Mahajan (opens in new tab), NRG researcher, to delve into the surprisingly complex issues that challenge the development of diagnostic tools for small networks. Together with colleagues Srikanth Kandula (opens in new tab); Patrick Verkaik (opens in new tab) of the University of California, San Diego; Sharad Agarwal (opens in new tab); and Jitendra Padhye (opens in new tab), Bahl and Mahajan developed NetMedic, a research prototype that addresses management problems inherent in small networks. The team presented NetMedic, and its accompanying technical paper, Detailed Diagnosis in Enterprise Networks (opens in new tab), during SIGCOMM 2009 (opens in new tab), the annual conference of the Association for Computing Machinery’s Special Interest Group on Data Communications.
It’s Not Easy Being Small
“When we first approached the problem,” Bahl says, “we looked at enterprise network-management systems, because the NRG has done a lot of work in this space and we believed we could leverage those solutions. But we soon realized that home and SMB networks raised entirely, qualitatively different issues.”
There are two reasons why simply scaling down enterprise solutions will not work for small networks: granularity and richness of topology. Enterprise diagnostics take a broad-brush approach to the problem; in large networks, where applications run on dedicated servers, pinpointing problems down to the server level is often enough for an experienced network administrator. But in a home or SMB network, a single server could run multiple applications, so troubleshooting needs to be more granular and must identify the problem more precisely.
Large networks also have a richer topology, with many server and client processes, so it’s easier to identify problem sources through fault correlation.
Mahajan offers a simple example.
“Victor and I have offices close to each other, but given the size and richness of our corporate network, he may connect to a different Web server than I do, even if we use the same router,” Mahajan says. “So if my browser slows down to a crawl while he experiences no problems, it’s very likely that the problem is due to the Web server I’m connected to and not our shared router.
“Such correlation-based logic is employed by diagnostic systems that were designed for large enterprises. But it does not work well for a small network, since there could be a single router and a single Web server.”
Another critical reason is that enterprises have more resources, more tools, and experienced, full-time network administrators, whereas the small business or home user will try to manage the network themselves or summon part-time help. It was obvious to the research team that the more handholding a diagnosis tool could deliver, the more valuable it would be for home and SMB users.
Paradoxical Goals … Maybe
“Whenever researchers enter a new domain,” Mahajan muses, “there is a lot of work around understanding the domain and framing it as a technical problem. And that was the case here, because SMB and home networks are messy. Each one is different. So how could we state the specific technical goal in a way that enabled us to define a consistent abstraction to represent this messy scenario?”
To add to their understanding of small-network problems, the researchers obtained data from one of the Microsoft Customer Service and Support groups. The researchers read through SMB case logs with the goal of classifying problems and causes, studying symptoms ranging from application-specific errors to performance and reachability issues, and classifying diverse underlying causes such as software bugs, configuration changes, and unexpected side effects from software updates.
While it is fairly straightforward to design solutions for each type of problem or application, it is challenging to design a system that accommodates all problems—a goal the researchers decided they would tackle.
“People have written systems that try to specify very fine-grain root causes,” Mahajan says, “but they’ve all been application- or domain-specific, such as the ones designed for Internet-service providers, who manage thousands of routers.”
The NetMedic team wanted a system that would diagnose application problems both specific and generic, identifying problem causes as granularly as possible: down to the faulty process, incorrect configuration, or incorrect update. The system also had to be application-agnostic, because it’s impossible for a general diagnostic system to contain knowledge of every possible application. These goals were seemingly paradoxical: to detect application-specific faults without any application knowledge.
For the researchers, their goals disqualified a rules-based approach, because, by definition, the system would need prior knowledge of applications and possible faults. The team decided to treat the work as an inference problem, to capture the behaviors and interactions of network components and to solve the challenge of determining when one component might be impacting another.
History Lessons
The researchers didn’t throw out everything from the enterprise space. They realized they could leverage some of the same concepts, applied differently. One thing they needed was a rich network model.
“One concept we liked was the notion of dependency graphs.” Bahl says. “These are valuable for modeling very complicated enterprise networks where you need to show which network components are dependent on each other. For SMB networks, that level of network complexity doesn’t exist, but we felt this was a strong concept that we could apply successfully to NetMedic.”
The researchers implemented this concept in NetMedic by first having it collect data about the network, then generating a dependency graph consisting of components such as application processes, host machines, and configuration elements. To represent interaction between components, an edge connects two components if the source directly impacts the destination.
Next, the team needed to solve how to determine reliably whether a component failure impacts another component.
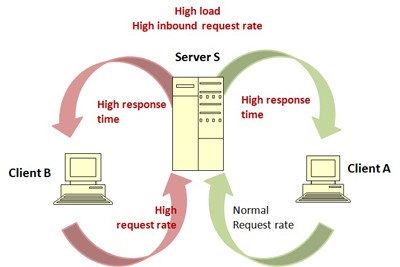
Current network-management systems for enterprises can identify an overloaded Server S as being responsible for Client A’s slow response times. NetMedic’s goal is to identify Client B as the true culprit.
“When you look at existing models based on dependency graphs,” Mahajan explains, “there is a rather binary status of faulty/healthy. If a component breaks, you assume that its dependent components also break. But this is not always true in a heterogeneous shared environment. For instance, an application might get overloaded and take up a lot of CPU cycles, but this only affects other applications if it consumes resources to the point where it slows down the system.
“Dependencies between components are complex, with different interactions and functionalities. To determine whether one component might be hurting another, we needed to capture more detail.”
Historical data provided the detail they needed. By monitoring component behavior and maintaining a historical database, NetMedic can compare abnormal component behavior to normal behavior. The result is a ranked list of the components most likely responsible for a problem. The combination of dependency graphs and historical data enabled the researchers to infer process interactions even though the dependency graph itself contained no knowledge of those interactions.
NetMedic in Action
The NetMedic prototype went through its paces in a live deployment consisting of a server and 10 active volunteers on desktop machines. The server hosted multiple applications, including a Microsoft Exchange e-mail server, an Internet Information Services Web server, and a Microsoft SQL Server database. The team instrumented the volunteers’ desktops and then injected faults similar to those documented in the case logs studied. NetMedic put the offending component at the top of the ranked list 80 percent of the time. In the other cases, NetMedic almost always managed to rank the culprit in the top five.
“Even if we don’t know how components interact,” Mahajan says, “we can use history about how the network has behaved to infer where the root cause may lie. We find that 30 to 60 minutes’ worth of history is sufficient for an accurate diagnosis.”
NetMedic has met the research team’s goal of providing more useful information and handholding to SMB network users and administrators by effectively pinpointing the source of network problems at a granular component level. Equally important to the researchers, NetMedic has proved that an application-agnostic network-management system is capable of detecting application-specific faults.
“The way the problem is framed is the power of the problem,” Bahl says. “We don’t assume any prior knowledge of the applications. Just by monitoring and collecting data, NetMedic figures out dependencies and relationships, and what is normal or abnormal behavior. That’s what all the reviewers loved when they read the technical paper. This general approach is quite powerful, and we hope to apply it in other settings someday.”
Speaking of the future, is the NetMedic team planning to extend this work into the realm of automatic problem repair?
Bahl and Mahajan laugh at the question.
“That’s the holy grail of network management.” Bahl says. “It falls under the bigger theme of self-managing networks, where a system can diagnose itself, figure out what’s wrong, fix the problem, or raise the alert. We’re not there yet!”
But Mahajan notes that providing more detail in identifying the root causes of problems makes it easier to go down that road.
“There will be another small technical challenge after that,” he says, smiling, “to ensure that your automated fixes don’t create unexpected side effects.”



