
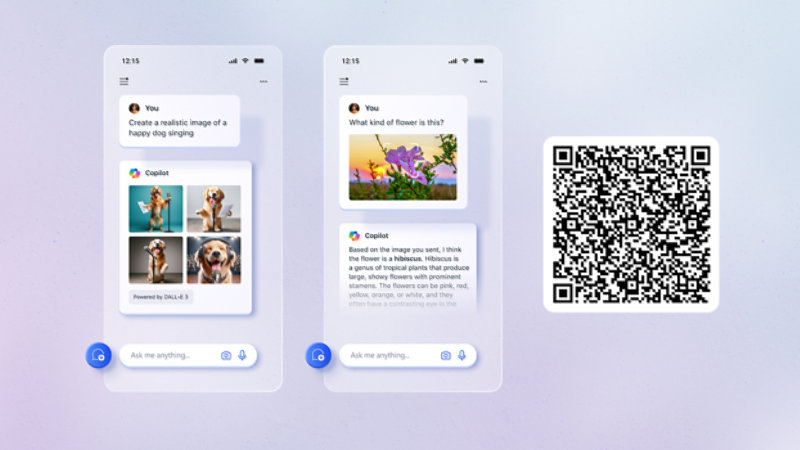
Unlock your potential with Microsoft Copilot
Get things done faster and unleash your creativity with the power of AI anywhere you go.
Speller Challenge TREC Data
This download is provided for the purpose of the Speller Challenge. Last published: January 14, 2011.
Important! Selecting a language below will dynamically change the complete page content to that language.
Version:
1.0
Date Published:
5/12/2016
File Name:
Speller Challenge TREC Dataset.zip
File Size:
329.5 KB
This download is provided for the purpose of the Speller Challenge. This is a development dataset based on the publicly available TREC queries (2008 Million Query Track). Queries are annotated by using the same guidelines and processes as in the creation of the Bing Test Dataset.Supported Operating Systems
Windows 10, Windows 7, Windows 8
- Windows 7, Windows 8, or Windows 10
- Click Download and follow the instructions.
Follow Microsoft