
By Suzanne Ross
People read stories to find out what happens next. That’s easy enough in a book, but if the story is about real life, and it’s online in the news media, it’s harder to find out what happens next. There’s just too much information out there. An Internet search will show you everything on a subject, regardless of whether it’s redundant information or a new twist. Then you have to filter the stories by clicking and reading every one.
Several Microsoft researchers have built an application that will analyze news on a word-by-word basis to make it easier for news junkies to follow the stories that they’re avid about, without having to manually filter information.
Microsoft Research Blog

Research at Microsoft 2024: Meeting the challenge of a changing world
In this new AI era, technology is changing even faster than before, and the transition from research to reality, from concept to solution, now takes days or weeks rather than months or years.
“We’ve built a general purpose infrastructure for representing collections of text, and for computing the differences between them. NewsJunkie can show you what you don’t know versus what you already know,” said Susan Dumais, a senior researcher in the Adaptive Systems and Interactive group. Evgeniy Gabrilovich, an intern in the ASI group, was instrumental in the development of the NewsJunkie infrastructure.
“I’m a news junkie,” said Eric Horvitz, the group’s manager. “I like to track stories to find out what’s new. When I look at news aggregation sites, I get frustrated because of the redundancy. I only want to know about the new developments. Many people feel just the way I do about redundancy.”
One of the stories Horvitz followed was a pizza deliveryman mystery in Pennsylvania that broke in the news near the start of the research project. The group used News Junkie to chart the story over time.
“The update application allows you to identify news stories over time that are likely to contain novel information. The initial stories were about a pizza deliveryman who robbed a bank with a bomb locked around his neck, saying he said he was being forced to rob the bank. The bomb went off and killed him while police stood back. In the first burst of novel information after the initial news, stories included reviews by neighbors about the man’s personality; he was a nice guy who lived with his cats. The next burst of news in the feed reveals that he was carrying a gun disguised as a cane, and then the next one was that police were looking for two people driving a Lincoln Continental. Then there was a copy-cat case in Missouri. Beyond identifying spikes of novel information in feeds, we began to characterize the type of story. Stories are not just follow up stories to the original one, but also recaps. We started to think about how we could characterize the fingerprint by looking at patterns within the document. We explored intra-document patterns identifying differences between an update, a recap, and offshoot stories,” explained Horvitz.
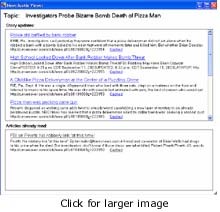 The NewsJunkie prototype has a two-paned window. The upper pane lists the stories that the user has shown interest in, and the lower pane is populated with the stories the user has already read. As each story is read, the upper list is filtered automatically to eliminate redundant articles and puts the newest stories at the top.
The NewsJunkie prototype has a two-paned window. The upper pane lists the stories that the user has shown interest in, and the lower pane is populated with the stories the user has already read. As each story is read, the upper list is filtered automatically to eliminate redundant articles and puts the newest stories at the top.
“For NewsJunkie, we decided to define interests by what was read, and then, given what you’ve read, find things that are on the same topic but novel, so that we could present new information to you,” said Dumais.
The same techniques could be used to analyze text collections other than news items. “We’re interested in applying these techniques to evaluate email,” said Horvitz. “That way, you could see how your communication changed over time.”
NewsJunkie can also evaluate collections of text to compare how two different sources present the same information, such as the same news event as reported by different countries, or competing news agencies.
“We look at differences in a set of things that are schematically related. The algorithms are pretty flexible. What they do is look at the words in the text, or rich entities such as people, places, or things. So in addition to identifying individual words, we can identify that the United States is a location, and that George Bush is a person,” said Dumais.
“We did some studies of information from different sources. We analyzed how news media from different countries were reporting on stories. We lined up the stories next to each other, and used statistical tools to highlight different patterns of words used to describe the same events. The differences are subtle but powerful. For example, when one group blew up a bus, a source that tends to be more sympathetic with the cause of the bombers reported the victims as passengers on a bus. Others reported it as schoolchildren on the way to school. It happens on both sides,” said Horvitz.
Horvitz holds out hope that they could use this type of analysis to help people understand the impact of their words-and the subtle or large differences in the thoughts behind their words. “It’s fascinating to think statistical methods could help people understand each other. Perhaps these methods could serve as a form of statistical ‘peace engine’ that could help people understand when they’re depersonalizing the other side’s viewpoints,” said Horvitz.
While NewsJunkie hasn’t been released as a product, the researchers have continued to work with the people who built NewsBot, a news service on MSN that gathers news from over 4,800 sources on the Internet. “It’s a good example of how research can influence product features at multiple levels,” said Horvitz.



