
Overview
This page contains supplementary material for our AAAI 2010 paper: “User-Specific Learning for Recognizing a Singer’s Intended Pitch”. The full citation for our paper follows, along with a link to the paper itself:
Guillory A, Basu S, and Morris D. User-Specific Learning for Recognizing a Singer’s Intended Pitch. Proceedings of AAAI 2010, July 2010.
For more information about this work, contact Dan Morris (dan@microsoft.com) and Sumit Basu (sumitb@microsoft.com).
Abstract
We consider the problem of automatic vocal melody transcription: translating an audio recording of a sung melody into a musical score. While previous work has focused on finding the closest notes to the singer’s tracked pitch, we instead seek to recover the melody the singer intended to sing. Often, the melody a singer intended to sing differs from what they actually sang; our hypothesis is that this occurs in a singer-specific way. For example, a given singer may often be flat in certain parts of her range, or another may have difficulty with certain intervals. We thus pursue methods for singer-specific training which use learning to combine different methods for pitch prediction. In our experiments with human subjects, we show that via a short training procedure we can learn a singer-specific pitch predictor and significantly improve transcription of intended pitch over other methods. For an average user, our method gives a 20 to 30 percent reduction in pitch classification errors with respect to a baseline method comparable to commercial voice transcription tools. For some users, we achieve even more dramatic reductions. Our best results come from a combination of singer-specificlearning with non-singer-specific feature selection. We are also making our experimental data available to allow others to replicate or extend our results, and we discuss the implications of our work for training more general control signals.
Supplementary Material
The primary purpose of this page is to host the data used in our experiments, which consist of:
- A series of MIDI tracks, each a short melody or scale, several measures long
- Recordings of 22 participants singing those melodies along with a drum beat, time-sync’d to the original MIDI tracks
We hope these recordings can serve as the beginning of a larger data repository, and as a benchmark data set for user-specific training or vocal melody transcription for environments with fixed tempos (an important feature of these recordings is that they were created by asking users to sing along with a drum beat).
Our complete experimental procedure is described in detail in our paper, and the instructions displayed to participants will be included at the end of this page. We note that only 22 recordings are included here, which is smaller than the total number collected: not all participants consented to having their recordings publicly released. However, the data set posted on this page is not systematically biased and is appropriate for testing alternate methods and understanding our experiments.
Our data archive can be downloaded as a single zipfile:
public_pitch_data.zip (560MB)
The archive contains two directories:
input_data
This directory contains the ground truth files in both MIDI and audio format. Each file is numbered and named to correspond to the recordings for each participant (described below). In some cases files are labeled as “male” or “female”; these represent the same melody in slightly different ranges to allow for reasonable reproduction by participants of both genders. Each example is included as a MIDI sequence (.mid), an “example” sequence (.wma) (this is what participants heard before they were asked to sing back each example), and an “accompaniment” sequence (this is what participants heard while they were singing back each example: just a drum beat, an initial cue to set the key, and a count-in voiceover.
For example, melody 2 is represented in this directory as six files (all of which are live links on this page, as examples):
02TwinkleFemale.accompaniment.wma
02TwinkleFemale.example.wma
02TwinkleFemale.mid
02TwinkleMale.accompaniment.wma
02TwinkleMale.example.wma
02TwinkleMale.mid
public
This directory contains recordings from 22 partipcants singing along with each of our 21 melodies. For example, the directory called “P004” contains participant 4’s recordings of all 21 melodies, so files are named:
00Easy1.training.wav
01Easy2.training.wav
02TwinkleMale.training.wav
03Diddle2Male.training.wav
…
21OdeToJoyMale.training.wav
The remainder of this page contains a brief video example of our data collection application, along with the instructions provided to participants, to demonstrate the process used for data collection. Please contact Dan Morris (dan@microsoft.com) and Sumit Basu (sumitb@microsoft.com) if you have questions about our procedure, are interested in implementing a competing method, or are interested in adding to our data repository!
Data Collection App Video Clip
Singing Experiment Instructions
This program will play and ask you to sing back a series of scales and melodies. We will use the data you record in our research into new pitch tracking methods which adapt to a singer’s voice. To participate, you will need a microphone. If possible, use headphones while recording and use an external microphone. If you don’t have a microphone or only have the microphone built into your computer, contact us and we can make alternate arrangements.As soon as you begin, you will be shown a sequence of notes in “piano roll” format. This will be used as a rough visual cue for the audio you will hear. We refer to each sequence of notes as an example. At the start of each example, you will hear the root note of the scale or melody and a 4 beat countdown. After the countdown, the notes on screen will play accompanied by a simple drum beat. Below is the interface you will see.

At the bottom of the screen is a volume meter which shows the volume level from your microphone. Blowing into the microphone should cause this meter to fill up all the way. When you’re singing the meter should fill about 1/4 to 3/4 of the way. Check the volume settings for your microphone if you don’t see the meter move or if your recording level is too high or low.After the example has played, we will ask you to sing back what you just heard. The same root note, countdown, and drum beat will play back immediately, and we ask you begin singing along with the drum beat after the countdown. There are no lyrics to sing in any of the examples. Instead sing “Doo” for each note as you might singing backup in an a capella group. When you are recording, the volume meter will turn red.
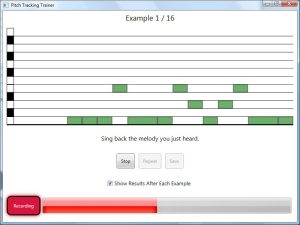
Recording will stop automatically, After you have finished recording, you will have the option to repeat the example again or move on the the next example. You will sing about 20 examples, and each example should take less than a minute to record. Optionally, after each example we will show you a visualization of the notes you sang and a score of how many notes you sang on pitch. Turn this option off if you find visualization is taking too much time.

Try your best, but it’s OK if many of the notes you sing are scored “wrong”. Automatic voice transcription is a difficult problem, and the algorithm we are using is unforgiving. This is in fact what we hope to improve using your data! When you’re done, we’ll create a zipfile of your data, and we’ll automatically transfer that zipfile to our experimental database. If you have questions email us.
When you are ready to begin, indicate your gender, enter your email address below, and click “Start”. Thank you for participating!
People

Andrew Guillory
Research Intern
Sumit Basu
Senior Principal Researcher